


Frankly Speaking, 4/9/19 -- Creating Private Browsing Everywhere
A weekly(-ish) newsletter on random thoughts in tech and research. I am an investor at Dell Technologies Capital and a recovering academic. I am interested in security, blockchain, and devops.

A couple of people have asked for their research work to be featured on my Weekly Tech Thought, which is awesome and welcomed! If there's a research project you want me to discuss, please send me an email with the paper and talk slides associated with them.
WEEKLY TECH THOUGHT
This week, I’m writing about one of my first PhD projects from around 2014. At the time, surprisingly, very few people cared about privacy. Incognito modes were novel concepts and much less prevalent than they are now. Ever since, there’s been rapid growth in the usage of search engines like DuckDuckGo and anonymous browsers like Tor. Today, every major browser has a version of incognito mode, and in fact, many users browse privately by default. To say the very least, people care a lot more about their privacy. I'll provide a summary of my work, and you can read the full paper here.
Problem
In private browsing mode, web pages shouldn’t leave identifiable, persistent client-side state. However, research has shown they are very leaky. For example, data can leak from the DNS cache, and databases can be polluted. Current instantiations of private browsing leave RAM artifacts in page swap and hibernation files. As a result, forensic tools can easily recover this data and fingerprint activity.
The problem is that private browsing is hard to implement with only client-side support. Browsers are complex and constantly adding new features, and they lack a priori knowledge of sensitive content. For example, to prevent RAM from paging to disk, the browser has to use mlock() to pin all the memory because it doesn’t know which part of a webpage will contain sensitive information. Even transmission of web content to a user can pollute in-memory and on-disk regions.
What if developers can implement private browsing semantics? The goal is to protect greppable content from a post-session attacker. A post-session attacker is an attacker that logs onto the same computer as a user after her session ends.
My Solution: Veil
Veil is the first platform that allows developers to private browsing semantics to a user. The insight is that web services control 1) the content they deliver and 2) the servers that deliver this content. Below shows an overview of the Veil platform.
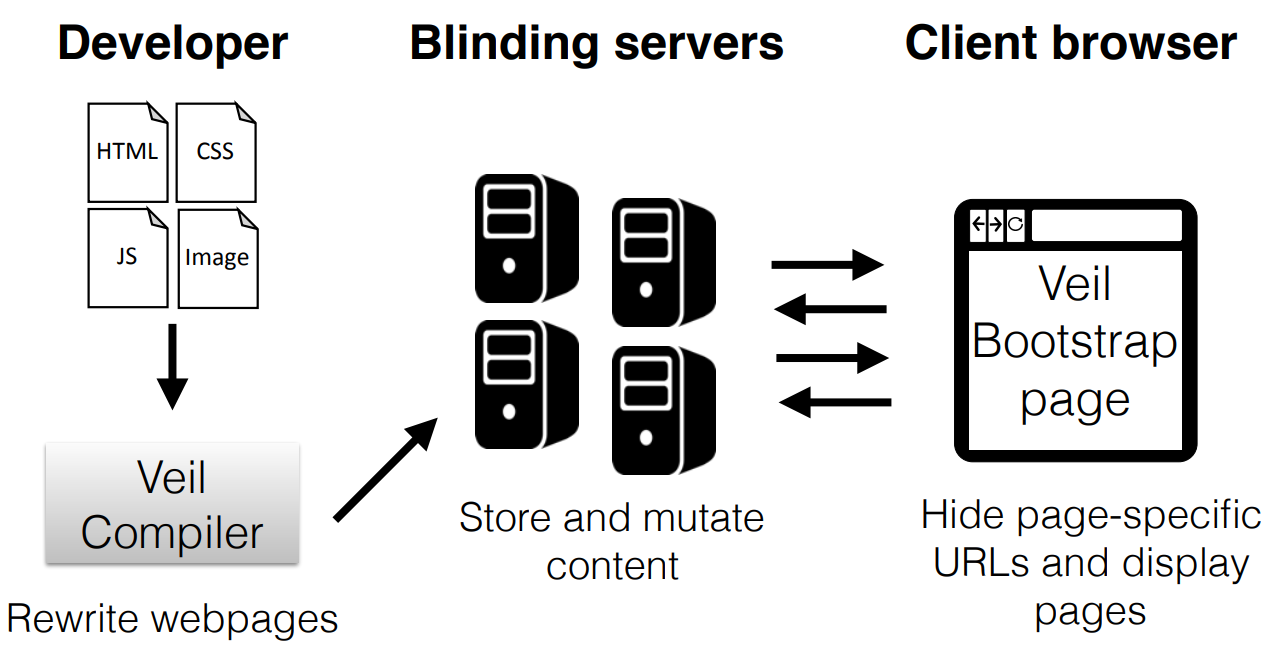
Below, I show how the Veil compiler works. A developer runs the root HTML file through the Veil compiler. The output is a rewritten HTML page with veilFetch instead of the actual object, such as CSS or image. Later, when the page loads, veilFetch (from the Veil library) will dynamically issue an XHR request to obtain the object.

The output of the Veil compiler is stored on the blinding servers. These servers are trusted and can be run by volunteers. These servers are a key source of security and privacy in Veil. They help mutate the content and also help hide the actual source of the object (e.g. hides Javascript source or source of JQuery, etc.).
In order to protect RAM artifacts, we use the following techniques:
heap walking: reduces likelihood of swap of objects passed into the markAsSensitive() function
content mutation: not leak site-specific content
More details on the specific techniques are available in the paper.
There is also a more secure browsing mode called DOM hiding mode, which tries to hide complex DOM structures. The idea is the user’s browser is just a thin client, and a remote server (e.g. the blinding servers or content provider) loads the real page, displays the screenshot on the browser, applies user GUI events, and returns the screenshot of the updated page.


Performance
Below are the page load times for six test web pages with and without Veil. Veil added modest overhead to the page load time.

To conclude, traditional private browsing modes still leak data! Veil allows developers to directly improve the privacy semantic of their pages without having to wait for Chrome or Firefox to modify their browsers.
The main motivation for this project was to change who controls trust on the web. Traditionally, web browsers have had the responsibility of dealing with security and privacy. This platform provides a way to shift the burden to developers.
WEEKLY TWEET

WEEKLY FRANK THOUGHT
I realize that my Frank Thought can be pretty long sometimes, and some topics are probably too complex to cover in one Frank Thought, especially what I am going to say this week. Consequently, I will be having multi-part Frank Thoughts.
This week, I want to discuss tech's recent obsession with data and "data-driven" approaches. Having and effectively using data is important, but it's definitely dangerous to blindly accept data as facts. As you can see, this is definitely part of a longer discussion, which will span a few weeks.
As a PhD student, I am constantly told that my results are meaningless unless they are put into context. In the same way, data itself is meaningless, but the interpretation of the data is useful. However, there are a couple of things to remember. First, correlation does not imply causation, which is rule number 1 in statistics, because there are confounding and unobservable variables. Second, interpretations have inherent biases. Finally, data itself can be biased, e.g. selection bias in how the data is collected.
This is why the use of the term "data-driven" to describe processes frustrates me. More times than not when someone uses this term, there is lack of rigor and precision in the process definition and creation. Even if the interpretation of the data is rigorous, the data collection methodology may not be.
We already know there are a lot of unintended consequences of using machine learning. Here is a good paper from MIT PhD student Harini Suresh describing a framework for understanding those consequences. As a society, we have seen machine learning unintentionally leading to housing discrimination or similarly robots being racist. So, it's important for us to be more rigorous and prudent in our use of data.
The point I'm trying to make is that just because something is "data-driven" doesn't make it any more correct or better. Collecting data and providing an interpretation based on it is a rigorous process, and we should regularly question methodologies and stop accepting data blindly. Just because we have a tool like machine learning, we shouldn't ignore the fact that it's based on statistics, which is a rigorous science.
Next week, I will dive more into the sources of bias in machine learning and what causes them.
FUN NEWS & LINKS
#securityvclogic
"Let's take pictures with CISOs and CIOs at events to show startups that we can introduce them to customers."
#delltechcapital
Faction*, managed service provider for VMware Cloud on AWS, raises 14M led by Dell Technologies Capital.
RiskLens*, a provider of cyber risk quantification and cyber risk management software, raised $20.55M in series B with participation from Dell Technologies Capital.
#research
Science isn't always about merit.
How bad can it get? Characterizing secret leakage in public GitHub repositories.
Calvin: fast distributed transactions for partitioned data systems.
#tech, #security, #vclife
Customer success: Best practices from the Experts
Micro-generational experiences
IBM Watson overpromised and underdelivered on healthcare AI.